Intro to Scale-Norming
Published 2 November 2020
Back to writingContents (click to toggle)
For my final year undergrad philosophy dissertation, I wrote about an apparently neglected problem relating to the measurement of subjective well-being. You might find this interesting (i) if you care about measuring and improving subjective well-being or life-satisfaction, and (ii) because I think it’s an intrinsically fun puzzle.
Interest in (measures of) subjective well-being (SWB) is growing within policymaking, social science, and effective altruist circles. But the philosophy of SWB is thorny territory. How does it relate to well-being overall? What cognitive mechanisms underlie self-reports of SWB? And how should distinct constructs, like life-satisfaction and affect, be combined? Relative to these questions, questions about the possibility, extent, and significance ‘scale-norming’ has been left by the wayside.
What is Scale-Norming?
In the general case, scale-norming occurs when a quantitative measure yields different absolute values relative to its target construct between or across measurements. Suppose I ask you to dunk your hand in a tub of water and rate how cold it feels to you out of 10. It’s chilly, so you give it an 8. A while later, I ask you to do the same thing with a different tub of water. The water is far colder than before — your subjective experience of cold is at least twice as intense. Of course, a response of 16 isn’t allowed, but a maxed-out answer of 10 seems to preclude the possibility of anything feeling colder. So you adjust your scale upwards, such that the same subjective coldness now yields a lower score out of 10. On this new scale, the extra-cold water scores a 9. With these two data points alone — a score of 8 for the first tub and 9 for the second — I don’t have enough information to determine whether you’ve used the same scale between trials.
Here’s a way of thinking about what’s going on here: you’re being asked to attach a number to subjective experiences, which don’t come pre-tagged with numbers, or with any obvious suggestions for how to match them up to numbers. So you’re forced to come up with some (necessarily kind of arbitrary) function which maps a point in ‘experience space’ onto a bounded scale from 0 to 10. Plenty of candidate functions could do that job, and you might reasonably change the function you use between trials. By ‘scale’ I just mean whatever function you end up using.
There is a second, distinct way in which dunking your hand in the tub of colder water could yield a surprisingly small change in reported coldness: it could literally not feel much colder than the previous trial. Maybe your hand got numb, or you otherwise acclimatised to the cold. Your function for mapping between experiences and scores doesn’t change, but the link between actual coldness and felt coldness does: now the same temperature of cold water yields a less intense feeling of coldness than it would have done had you not dunked your hand into the first tub, and it takes colder water to yield the same felt coldness. This is called adaptation.
In this way, we might imagine a two-stage process linking the absolute temperature of the water with your rating of experienced coldness. First, the water produces an experience of coldness. Then, you translate that experience into a numerical score. Adaptation pertains to the first link, scale-norming to the second.
As applied to measures of SWB, scale-norming occurs when the the scale I use for reporting my SWB changes compared to your scale, or my scale at a different time. Suppose I move from a small town to the big city between successive survey rounds. On the first round, I place my SWB at 7 points out of 10. I get a better job in the big city, and my eyes are opened to new opportunities I hadn’t previously considered. I’m objectively happier, but my bar for what counts as a 6, 7, or 8 out of 10 has also increased, and by an even greater amount. Therefore, I place my SWB at 6.5 out of 10 on the second survey round. My absolute score decreased, but only because I adjusted my scale.
Let’s focus on life-satisfaction, the most relevant SWB construct. When social scientists set out to measure life-satisfaction, they ask questions like this one:
Please imagine a ladder, with steps numbered from 0 at the bottom to 10 at the top. The top of the ladder represents the best possible life for you and the bottom of the ladder represents the worst possible life for you. On which step of the ladder would you say you personally feel you stand at this time?
Maybe we can model the thought process with two analogous steps. First, you decide or notice how satisfied with your life you in fact are. Then you need to establish what “the best possible life” and “the worst possible life” could mean, and thus what function to use for mapping your actual life satisfaction onto a point on this continuum. Applying this function yields a numerical score. Note that this is just a convenient model: presumably few people do this explicitly and in order.
On this view, there are two opportunities for the same same objective circumstances to yield a different score across times or people, or for different circumstances to yield the same or surprisingly similar scores. One is scale norming, when I change the function I use to map life-satisfaction onto some number between 0 and 10. The other is (hedonic) adaptation, where my actual life-satisfaction adjusts relative to the same objective circumstances. Suppose I win the lottery. For the first few months, I’m overjoyed. Eventually, my wealth becomes a new normal. I want a supercar in place of my sports car; a pool in place of my hot tub. In sum, I’m hardly more satisfied with my life compared to before I won the lottery. My scale use might not have changed at all, but my life-satisfaction scores over time might have shown surprisingly little change relative to the large change in objective circumstances.
Note how this assumes there is such a thing as ‘actual’ life satisfaction which is conceptually distinct from ‘whatever people put down on a life-satisfaction questionnaire’. By this, I mean the construct SWB researchers should be interested in — how happy people in fact are. Some people disagree that the notion of latent life-satisfaction is meaningful. Instead, they argue, it either gets formed on the spot in the reporting process or is just analytically equivalent to whatever score people decide to give.
Adaptation is real, pervasive, and powerful. This is depressing or uplifting depending on its direction. In a classic study, Brickman et al. (1978) compared a sample of winners of major lotteries to a sample of paralysed accident victims and a control group. The experimenters asked participants to rate how happy they were with life at the time of the interview, and before either winning the lottery or having the accident. Lottery winners reported a negligibly small improvement in present ‘general happiness’ relative to the control group (4.00 versus 3.82), while the (paraplegic and quadriplegic) accident victims reported being only marginally less happy than the controls. When all three groups were asked to rate the happiness they derive from a variety of mundane tasks, the lottery winners even reported a lower happiness relative to the other two groups.
Notice that when the raw numbers from life-satisfaction questions come back and show surprisingly small changes in the aftermath of significant changes, the measure is doing its job: it is accurately tracking the target construct (actual life-satisfaction) and telling us something potentially useful or illuminating about it. On the other hand, when scale-norming does occur, and we don’t point this out or re-adjust the numbers, the measure has basically failed to that extent. My ‘coldness’ scores of 8 and 9 obscure the fact that the second tub of water felt heaps colder than the first. Equally, if different scales are used across populations or between successive survey rounds for the same populations, then the resulting (unadjusted) statistics will not accurately reflect differences and changes in actual SWB. This would be bad, not least because policy is constructed on the basis of these statistics. One notably implication of taking SWB scale-norming seriously is that measures of economic development might relate to SWB more closely than they already seem to do. Here’s Tyler Cowen —
The observation of a nearly flat happiness-wealth relationship says more about the nature of language than it does about the nature of happiness… Kenyans have recalibrated their use of language to reflect what they can reasonably expect from their daily experiences.
There is some evidence that SWB scale-norming actually occurs in the context of migration. In a longitudinal study of successful Tongan applicants to the New Zealand visa lottery, Stillman et al. (2015) conducted SWB surveys at annual intervals before and after migration. Although moving from Tonga to New Zealand involves an improvement in objective economic circumstances, a measure of happiness taken from a five-question assessment of overall mental health (the MHI-5 scale) showed a small decrease, along with a measure of self-rated social respect, while a question about objective welfare showed a negligible change. When asked to make retrospective evaluations about prior to moving, the migrants indicated that their self-rated social respect and objective welfare had risen. Note that these measures are different from life-satisfaction, which is what I’m mainly interested in, but they suggest the possibility of scale-norming in similar measures.
What Causes Scale-Norming?
The Cowen quote above suggests a linguistic mechanism for scale-norming: differences in the interpretation of the wording of SWB questionnaires. Perhaps it’s just the case that, “less happy societies often attach less ambitious meanings to the claim that they are happy”.
Alternatively, an individual might be inclined to readjust their scale usage if their previous SWB rating is close to either bound of the closed numerical scales used in SWB surveys — like adjusting the sensitivity of a microphone to avoid ‘clipping’. More often this is the upper bound — the so-called ‘ceiling effect’ — as when you adjust your ‘coldness’ scale with the new tub of extra-cold water.
Thirdly, the most salient reference points or counterfactual circumstances might change relative to the individuals’ actual objective circumstances and SWB. Consider a rural household in a developing country witnessing the emergence of an urban middle class; or learning about the lives of affluent foreigners through hearsay, television, or the internet. While previously a 10/10 score may have implicitly represented the best life possible for some narrow community, now it might come to represent this new and improved (perceived) quality of life. This shift in reference points counts as scale-norming to the extent that it doesn’t affect actual latent happiness or life-satisfaction. To the extent that it does, shifting reference points counts as adaptation. This is commonplace, of course — endlessly greener grass does make us genuinely dissatisfied.
Finally, either the wording of survey questions or the quantitative scales they generate may vary between successive survey rounds. This might seem suspect, because the source of the change is not psychological, and endogenous to the survey itself. But it counts! Indeed, this cause accounts in part for the so-called ‘Easterlin paradox’: the (mostly discredited) observation that economic growth appeared to be uncorrelated with improvements in measured life-satisfaction over time for a number of developed countries. That’s because, as Stevenson and Wolfers (2008) point out, some of the life-satisfaction questions which Easterlin (1974) relied on changed their wording over time. The correlation between SWB and GDP within comparable survey periods is more clearly positive.

Another clear (and startling) example of this kind of ‘endogenous’ scale-norming is the Flynn effect: the observation that continual scale renormalisation conceals sustained and significant improvements in IQ test aptitude (and actual general intelligence to some extent). Since, by convention, the test results are always standardized around an average score of 100 for that cohort, comparing unadjusted results at different times obscures these changes. The Flynn effect is instead made clear when older tests are taken in conjunction with newer ones by the same people.
Identifying Scale-Norming
If scale-norming is real, it’s going to be useful to know how to investigate the extent to which it occurs in various contexts, and then normalise the raw measures accordingly. How might we do that?
1. Recall
The reason the study of Tongan migrants suggests scale-norming is because the migrants reported large improvements which were not fully reflected in the actual past results. This suggests a method for identifying scale norming. Consider two successive measurements and from the same individual at times and respectively, where the numerical measure ranges from 0 to 10. Ask the individual at to rate both their present SWB (specifically, life-satisfaction) and their recalled SWB at , using the same (present) scale. This should be made explicit: e.g. “how would you have scored your life-satisfaction at if you were to use the scale / criteria you used to score your present life-satisfaction?”. Call this second rating . If is significantly different from , infer scale-norming. On a new scale, take the initial rating at as a fixed point, and adjust the new measure for to . This can be applied iteratively, over multiple successive survey rounds. Interpreted graphically, the result is a single line within a kind of ‘worm’ which tracks changes in SWB on a single scale, and displays the scales used at successive times in terms of a single scale; enabling comparisons across time. The resulting scale might no longer range from 0-10 on ’s original scale:

An alternative explanation for the difference between recalled and measured SWB is biased recall — maybe the respondents are using the same scale but misremembering the past. One reason to think scale-norming better explains these discrepancies is that recall seems to typically be biased in the direction of idealising the past, whereas the Tongan migrants would have to be taking an inaccurately gloomy view of their past.
2. Reference Class
Suppose you wanted to know whether two populations used different scales. Retrospective measures are likely to be useless here. To give a blunt example: you cannot ask a congenitally blind person how much happier they were when they could see. Instead, you might pose questions to both groups about projected well-being under different circumstances — questions of the kind “how happy would you expect to be under circumstances x, y, and z?”.
The idea here is that if the ‘projected’ scores for are lower for one group, then that group plausibly has higher criteria in terms of actual or latent SWB for the same numerical ratings. This can be extended by asking the survey respondents to rank both their own SWB and that of the other group among the other counterfactual circumstances (using the same scale they use for self-reports). On this approach, overall differences in scores for the counterfactual reference classes count as evidence that the populations are using different scales. Just as in the recall approach, the measures derived from the two groups might be rendered comparable by adjusting the SWB scores for one or both groups so that their scores for the reference class match. After normalising the responses in this way, the residual difference between one group’s self-reported SWB and the other group’s estimate of their SWB might then count as an instance of surprising or unexpected adaptation.
Claiming that one population on the whole uses a different scale to another, or just that two individuals use different scales, assumes that interpersonal comparisons of utility are possible. I’m flagging that because there’s room to disagree — maybe my happiness is my happiness and yours is yours and that’s that.
Interesting fact on roughly this topic: people tend to dramatically underestimate the happiness of those around them.
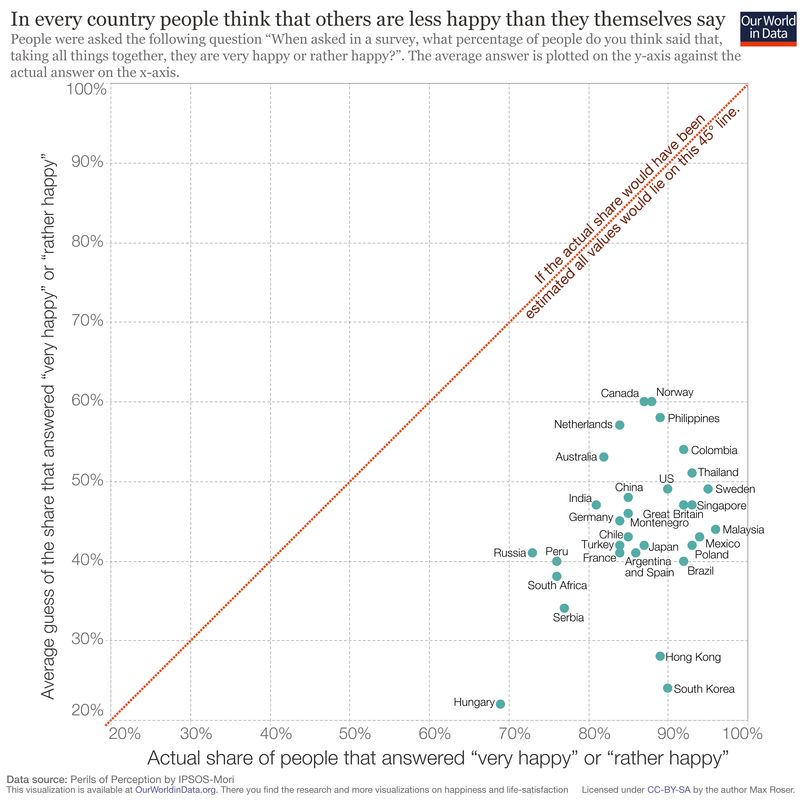
3. Affect and ‘Objective Happiness’
Subjective well-being encompasses at least two distinct constructs: life-satisfaction and affect (often further split into positive- and negative-affect). Life-satisfaction (LS) is a cognitive judgement: the result of reflecting on my life as a whole, incorporating or ignoring whatever facts I think are (ir)relevant. Affect is more like a fact about the quality or valence of my moment-to-moment experience: am I in a good mood right now? LS and affect come apart in theory and practice — for instance, Kahneman and Deaton found that high income improves measures of LS but not affect.
Although much is known about how LS and affect in fact covary, it’s possible to disagree about how they relate in terms of accuracy conditions, and in terms of value. On these questions, some argue that what ultimately matters is just the amount of positive affect in your life — the integral of affect over time. On this view, measures of life-satisfaction are useful because they’re normally pretty good proxies for affect — but just increasing LS should not amount to an end in itself. It’s no small leap to then suppose that your balance of affect constitutes something like accuracy conditions for a self-evaluation of one’s life. If somebody rates their life-satisfaction at an 5 out of 10, it’s obviously inappropriate to leap up and yell, “Aha! Wrong!”. But it might be reasonable to point out that this person was fairly happy for most of the year, but that certain biases in recall led them to more readily remember the low points, and so maybe their LS score ought to have been higher (or vice-versa).
This line of thinking motivates a third method for identifying scale-norming. Momentary assessments of affect — how happy are you right now? — are not vulnerable to such distortions of memory. They are also less prone to be influenced by contextual considerations about how I stand in relation to my broader circumstances — factors which strongly influence ‘all things considered’ questions about LS. So it seems reasonable to assume that measures of momentary affect are less prone to scale-norming than measures of LS. If your philosophical views sanction it, this suggests we might identify scale-norming in measures of LS by relating them to frequent measures of affect. For instance, in addition to conducting a survey with an LS question, you might get a subsample to feed back responses over much shorter timescales with e.g. a mobile app that randomly prompts participants to rate to rate how their day’s going. Suppose a cohort’s recalled affect over the past month increases between successive survey rounds by 10%, while aggregated momentary affect improved by 20%. This might (tentatively) suggest that the cohort have renormalised their scales downwards by 10% relative to their ‘objective’ happiness.
None of these methods are going to be able to unequivocally identify instances of scale-norming. Some alternative explanation always exists. In the case where my recalled SWB for this time last year is lower than the score I in fact gave, perhaps my scale hasn’t changed but my recall is biased. In the case where I estimate my SWB in a range of counterfactual scenarios, and my average hypothetical SWB score changes compared to last year, perhaps I’ve only changed my mind about how I would fare in non-actual scenarios. And when my momentary affect is lower on average this year compared to last, but my life-satisfaction scores are higher — maybe I just care about things other than affect (like having completed a stressful but meaningful project). That these alternative explanations always exist is no coincidence, because the idea of a ‘scale’ for SWB is slippery at best. There is no noncontroversial, objective measure of a person’s ‘real’ SWB beyond the reports they give.
Take a more innocuous example. Consider a survey which asks respondents how much they drink in a typical week, and how much they were drinking in a typical week this time last year. If the scale is expressed in units of alcohol, then in principle a response can be checked against the respondents actual drinking habits (see this paper for an application to smoking). This way, your responses can be straightforwardly described as accurate or inaccurate, and your recall of last year is biased or not. If the scale is a numerical scale between 0 for ‘none’, 5 for ‘a fair amount’, and 10 for ‘a great deal’, it becomes far less clear whether (for instance) I’m drinking more this year, or I’ve just adopted stricter standards for what counts as drinking a ‘fair amount’. So the possibility of scale-norming arises from ambiguities in how the suggested numerical scale should map on to the thing being measured. The reason scale-norming is philosophically interesting is that there is no equivalent of the objective measures like ‘units of alcohol’. For some, an ‘objective’ measures of SWB is flatly incoherent: a life-satisfaction score of 7/10 just is whatever I choose it to mean, and there’s no further or underlying fact of the matter which I’m ‘translating’ into a score. But I think it’s at least plausible that SWB is more like alcohol consumption, in that there is something like a real, latent construct that is being revealed rather than invented through giving an LS score.
Conclusion
I’m unsure about the actual extent and severity of scale-norming in SWB self-reports. I am convinced that it’s a coherent possibility, and that it probably occurs at least in some contexts some of the time. I don’t expect any huge revelation where results previously attributed to hedonic adaptation are reassessed as instances of scale-norming; maybe scale-norming explains something like 2-20% of the unexpected differences between measured and expected SWB depending on the context, possibly less. In part that’s because I haven’t looked at much of the relevant empirical literature, and in part that’s because there doesn’t seem to be much directly revelant evidence at all.
It’s a trope to conclude by remarking that questions remain unanswered and more work is needed etc., but I really do think more work is needed here. The philosophy and measurement of subjective well-being matters enormously — because subjective well-being matters, and because these measures are increasingly dictating policy irrespective of whether it does. In particular, I see scope for investigating the processes and mechanisms underlying reports of life-satisfaction and positive or negative affect.
Further Reading
Mark Fabian’s paper Scale-Norming Is a Concern for Life Satisfaction Research: Evidence From a New Metric is to my knowledge the only article that directly addresses the topic of scale-norming in the context of SWB. Note that (by his own admission) it slightly misinterprets the results of the Tongan migrant study.
Here are some other interesting and/or relevant articles, in no particular order:
- Memories as anchors: Novel analyses on the intrapersonal comparability of wellbeing reports — Caspar Kaiser (2020)
- Feeling Good or Feeling Better? — Alberto Prati and Claudia Senik (2020)
- A Philosophy for the Science of Well-Being — Anna Alexandrova (2017)
- The Nature and Significance of Happiness — Dan Haybron (2013)
- High income improves evaluation of life but not emotional well-being — Daniel Kahnemann and Angus Deaton (2010)
- Objective Happiness — Daniel Kahnemann (1999)
- Are they really that happy? Exploring scale recalibration inestimates of well-being — Heather Lacey (2008)
- Philosophical perspectives on response shift — Leah McClimans (2012)
- Happiness and Life-Satisfaction — Estaban Ortiz-Ospina and Max Roser (2017)
- Transformative Experience — L. A. Paul (2014)
- Doing Good Badly? Philosophical Issues Related to Effective Altruism — Micheal Plant (2019)
- Miserable Migrants? Natural Experiment Evidence on International Migration and Objective and Subjective Well-Being — Steven Stillman (2015)
Back to writing